Selective Convolutional Descriptor Aggregation
for Fine-Grained Image Retrieval
 |
Authors
Abstract
Deep convolutional neural network models pre-trained for the ImageNet classification task have been successfully adopted to tasks in other domains, such as texture description and object proposal generation, but these tasks require annotations for images in the new domain. In this paper, we focus on a novel and challenging task in the pure unsupervised setting: fine-grained image retrieval. Even with image labels, fine-grained images are difficult to classify, let alone the unsupervised retrieval task. We propose the Selective Convolutional Descriptor Aggregation (SCDA) method. SCDA firstly localizes the main object in fine-grained images, a step that discards the noisy background and keeps useful deep descriptors. The selected descriptors are then aggregated and dimensionality reduced into a short feature vector using the best practices we found. SCDA is unsupervised, using no image label or bounding box annotation. Experiments on six fine-grained datasets confirm the effectiveness of SCDA for fine-grained image retrieval. Besides, visualization of the SCDA features shows that they correspond to visual attributes (even subtle ones), which might explain SCDA’s high mean average precision in fine-grained retrieval. Moreover, on general image retrieval datasets, SCDA achieves comparable retrieval results with state-of-the-art general image retrieval approaches.
Highlights
Unsupervised Fine-Grained Objects Localization
 |
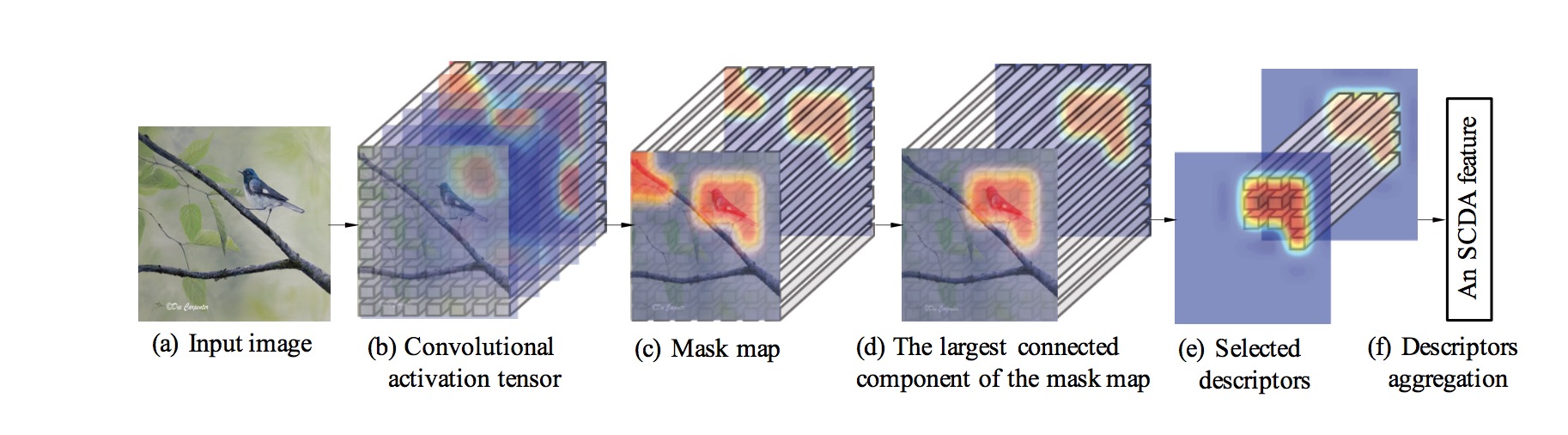
Sampled feature maps of fine-grained images from five fine-grained datasets (CUB200-2011, Stanford Dogs, Oxford Flowers, Aircrafts and Cars). Although we resize the images for better visualization, our method can deal with images of any resolution. The first column of each subfigure are the input images, and the randomly sampled feature maps are the following four columns. The last two columns are the mask maps M and the corresponding largest connected component 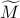 . The selected regions are highlighted in red with the black boundary.
. The selected regions are highlighted in red with the black boundary.
Fine-Grained Image Retrieval Accuracy
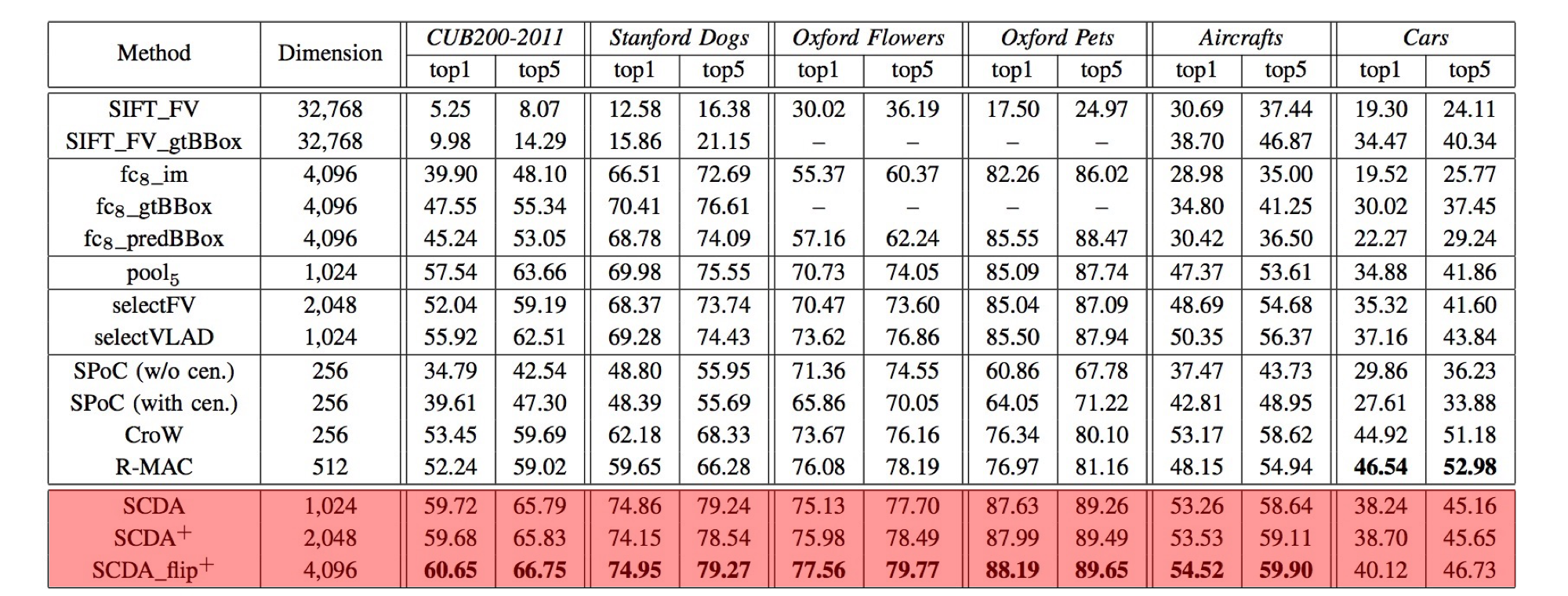 |
In general, the proposed SCDA_flip+ is the best amongst the compared methods. Comparing with these results with the ones of SCDA, we find the multiple layer ensemble strategy (cf. Sec. III-D in the TIP paper) could improve the retrieval performance, and furthermore horizontal flip boosts the performance significantly. Therefore, if your retrieval tasks prefer a low dimensional feature representation, SCDA is the optimal choice, or, the post-processing on SCDA_flip+ features is recommended.
Quality and Insight of the SCDA Feature
 |
Quality demonstrations of the SCDA feature. From the top to bottom of each column, there are six returned original images in the descending order of one sorted dimension of the “256-d SVD+whitening” SCDA feature. Images of each column have some similar “attributes”, e.g., living in water and opening wings for birds; brown and white heads and similar looking faces for dogs; similar shaped inflorescence and petals with tiny spots for flowers; similar poses and propellers for aircrafts; similar point of views and motorcycle types for cars. Obviously, the SCDA feature has the ability to describe the main objects’ attributes (even subtle attributes). Thus, it can produce human-understandable interpretation manuals for fine-grained images, which might explain its success in fine-grained image retrieval.
Summary of Experimental Results
We summarize several empirical observations of the proposed selective convolutional descriptor aggregation method for FGIR.
Simple aggregation methods such as max- and average-pooling achieved better retrieval performance than high-dimensional encoding approaches. The proposed SCDA representation concatenated both the max- and average-pooled features, which achieved the best retrieval performance as reported in Table II and Table III (both are in our TIP paper).
Convolutional descriptors performed better than the representations of the fully connected layer for FGIR. In Table III, the representations of “pool5”, “selectFV” and “selectVLAD” are all based on the convolutional descriptors. No matter what kind of aggregation methods they used, their top-k retrieval results are (significantly) better than the fully connected features.
Selecting descriptors is beneficial to both fine-grained image retrieval and general-purposed image retrieval. As the results reported in Table III and Table VI, the proposed SCDA method achieved the best results for FGIR, meanwhile was comparable with general image retrieval state-of-the-art approaches.
The SVD whitening compression method can not only reduce the dimensions of the SCDA feature, but also improve the retrieval performance, even by a large margin (cf. the results of Aircrafts and Cars in Table V). Moreover, the compressed SCDA feature had the ability to describe the main objects’ subtle attributes, which is shown in Fig. 8.
Related Papers
X.-S. Wei, J.-H. Luo, J. Wu, and Z.-H. Zhou. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. IEEE Transactions on Image Processing (TIP), 2017, 26(6): 2868-2881. [code]
X.-S. Wei, J.-H. Luo, and J. Wu. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. arXiv:1604.04994, 2016. [slide] [code]