《解析深度学习——卷积神经网络原理与视觉实践》(开源电子版)
作者
出版社
电子工业出版社
图书
前言
人工智能,一个令人熟悉但却始终倍感陌生的词汇。让人熟悉的是科幻作家艾萨克·阿西莫夫笔下的《机械公敌》和《机器管家》,令人陌生的却是到底如何让现有的机器人咿呀学语邯郸学步;让人熟悉的是计算机科学与人工智能之父图灵设想的“图灵测试”,令人陌生的却是如何使如此的高级智能在现实生活中不再子虚乌有;让人熟悉的是2016年初阿尔法狗与李世石的五番棋对决,令人陌生的却是阿尔法狗究竟如何打通了“任督二脉”……不可否认,人工智能就是人类为了满足自身强大好奇心而脑洞大开的产物,现在提及人工智能,就不得不提阿尔法狗,提起阿尔法狗就又不得不提到深度学习。深度学习究竟为何物?
本书从实用角度着重解析了深度学习中的一类神经网络模型——卷积神经网络,向读者剖析了卷积神经网络的基本部件与工作机理,更重要的是系统性的介绍了深度卷积神经网络在实践应用方面的细节配置与工程经验。笔者希望本书“小而精”,避免像某些国外相关书籍一样浅尝辄止的“大而空”。
写作本书的主因源自笔者曾于2015年10月在个人主页上开放的一个英文深度学习学习资料“深度神经网络之必会技巧”(Must Know Tips/Tricks in Deep Neural Networks)。该资料随后被转帖至新浪微博,颇受学术界和工业界朋友好评,至今已有逾31万的阅读量,后又被国际知名论坛KDnuggets和Data Science Central特邀转载。期间曾接收到不少国内外读过此学习资料的朋友微博私信或邮件来信表示感谢,其中不乏有人提到希望开放一个中文版本以方便国人阅读学习。另一方面,随着深度学习领域发展的日新月异,当时总结整理的学习资料现在看来已略显滞后,一些最新研究成果并未涵盖其中,同时加上国内至今尚无一本侧重实践的深度学习方面的中文书籍。因此,笔者笔耕不辍,希望将自己些许的所知所得所感及所悟汇总于本书中,分享给大家供学习和查阅。
这是一本面向中文读者轻量级、偏实用的深度学习工具书,本书内容侧重深度卷积神经网络的基础知识和实践应用。为了使更多不同技术背景的读者通过本书对卷积神经网络和深度学习有所了解,笔者试图尽可能少的使用晦涩的数学公式而尽可能多的使用具体的图表形象表达。本书的受众为对卷积神经网络和深度学习感兴趣的入门者,以及没有机器学习背景但希望能快速掌握该方面知识并将其应用于实际问题的各行从业者。为方便读者,本书附录给出了一些相关数学基础知识简介。
全书共14章,除“绪论”外可分为2个篇章:第一篇“基础理论篇”包括第1~4章,介绍卷积神经网络的基础知识、基本部件、经典结构和模型压缩等基础理论内容;第二篇“实践应用篇”包括第5~14章,介绍深度卷积神经网络自数据准备始,到模型参数初始化、不同网络部件的选择、网络配置、网络模型训练、不平衡数据处理,最终直到模型集成等实践应用技巧和经验。另外,本书基本在每章结束均有对应小结,读者在阅读完每章内容后不妨掩卷回忆,看是否完全掌握此章节重点。对卷积神经网络和深度学习感兴趣的读者可通读全书,做到“理论结合实践”;对于希望将深度卷积神经网络迅速应用来解决实际问题的读者,也可直接参考第二篇的有关内容,做到“有的放矢”。
本书写作过程得到笔者很多同学和学术界工业界朋友的支持和帮助,在此谨列出他们的姓名以致谢意(按姓氏拼音序):高斌斌,高如如,罗建豪,屈伟洋,谢晨伟,杨世才,张晨麟。感谢高斌斌和罗建豪帮助起草本书第3.2.4节和第4章的有关内容。此外,特别感谢南京大学、澳大利亚阿德莱德大学等高校的众多师长在笔者求学科研过程中不厌其烦细致入微的指导、教育和关怀。最后非常感谢笔者的父母,感谢他们的养育和一直以来的理解、体贴与照顾。写就本书,笔者自认才疏学浅,仅略知皮毛,更兼时间和精力有限,书中错谬之处在所难免,若蒙读者不弃还望不吝赐教,将不胜感激。
声明
本书可免费用于学习和研究目的,可自由传播,但切勿擅自用于商业用途或私自引用,版权所有,侵权必究。
本书勘误烦请发送邮件至weixs.gm
 gmail.com。
gmail.com。本书版本为17.05,成书于2017年五月。
由于个人时间精力有限,非勘误的学习问题恕难回复,还望海涵。
电子版下载
 |
戳此下载!(大文件版,51.3MB)(若无法访问,可尝试下方外链网盘。) 戳此下载!(小文件版,5.7MB)(若无法访问,可尝试下方外链网盘。) |
网盘
勘误
p.32, 第二段倒数第四行:“Transactions on Pattern Recognition and Machine Intelligence” —> “Transactions on Pattern Analysis and Machine Intelligence”
p.39, 图2.7图中文字说明:“池化” —> “汇合”
p.44, 第3.1.1节第一段:“感受野(receptive filed)” —> “感受野(receptive field)”
p.45, 图3.1:“填充(padding)操作示例” —> “感受野映射关系示例”
p.53, 第3.2.2节倒数第二行:“增加而不极具减小” —> “增加而不急剧减小”
p.60, 表3.1中22一行,参数信息:“
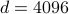 ” —> “
” —> “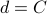 ”
”p.62, 表3.3中31一行,最大值汇合操作参数信息:“
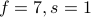 ” —> “
” —> “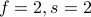 ”
”p.62, 表3.3中32一行,全连接层输入数据维度:“
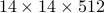 ” —> “
” —> “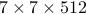 ”
”p.62, 表3.3中38一行,参数信息:“
” —> “”p.86, 第5.2.2节:“扣取” —> “抠取”
p.91, 正文倒数第二行:“鲁邦” —> “鲁棒”
p.92, 第7.2节第二段第一行:“个数位” —> “个数为”
p.93, 倒数第二段倒数第三行:“输入数据
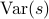 和输出数据
和输出数据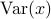 ” —> “输出数据和输入数据”
” —> “输出数据和输入数据”p.93, 倒数第二段倒数第二行:“
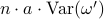 ” —> “
” —> “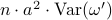 ”
”p.94, 第二段第四行:“尤其是在33层这种更深层的卷积网络上” —> “尤其是在30层这种更深层的卷积网络上”
p.95, 代码段分别第一段和第二段的第六行:“rand_param = a + (b-a) .* rand(n_in, n_out);” —> “rand_param = low + (high-low) .* rand(n_in, n_out);”
p. 104, 图8.4标题:“ReLU函数及其函数梯度” —> “ReLU函数及其变种”
p.119, 式10.2:“
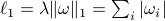 ” —> “
” —> “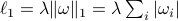 ”
”p.128, 图11.2横轴坐标:“训练论数” —> “训练轮数”
p.132, 倒数第二行:“全局学习率
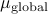 ” —> “全局学习率
” —> “全局学习率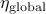 ”
”p.134, 第11.2.5节第一行:“层提到” —> “曾提到”
p.134, 第11.2.5节第二点第三行:“高层语义特征更新可能和程度较大” —> “高层语义特征更新可能或程度较大”
p.139, 最后一行:“数据下采样” —> “数据上采样”
p.142, 公式12.3上一行:“确保有效惩罚权重不小于1” —> “确保有效惩罚权重为正整数”
p.145, 第13.1.1节:“扣取” —> “抠取”
p.163, 行范数:
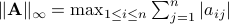 —>
—> 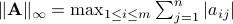
p.165, 公式B.2等号左侧:
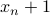 —>
—> 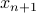
p.167, 正文倒数第三行:“鲁邦” —> “鲁棒”
p.168, 第五行:
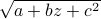 —>
—> 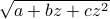
鸣谢
(按姓氏拼音序)
戴方勤,杜佳慧,胡泽田,贾添植,金鑫,罗晶,缪东旭,万坤鑫,万震,王嘉炜,汪宁,汪洋,魏文戈,赵明阳,张扬